Note: Alina Kloss has transitioned from the institute (alumni).
|
|
Description | Available at | |
|
Pushing Data
|
Extension of the MIT Push Dataset for planar pushing with code to
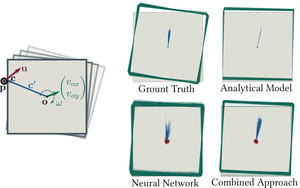
Used in Combining learned and analytical models for predicting action effects
|
To use the code: 1) Download the MIT Push Dataset 2) Download code for preprocessing, rendering and annotation of contact points and normals from here. We thank Kuan-Ting Yu and Maria Bauza for sharing the MIT Push Dataset and hosting the code.
|