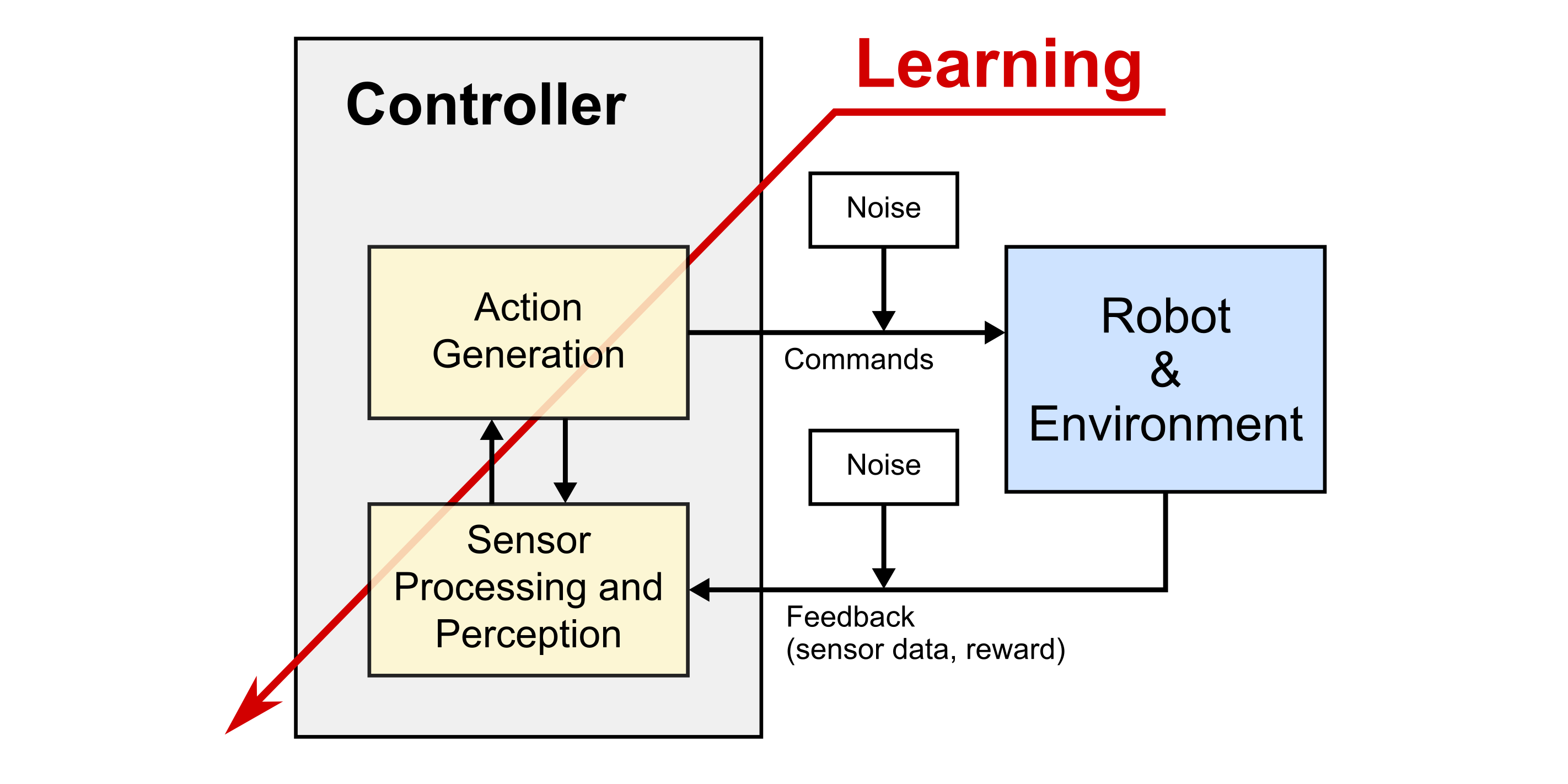
Abstraction of an autonomous system. The controller, which is typically implemented on the robot’s embedded computer, receives data from various sensors, processes the data, and computes new action commands to be executed by the robot. It is through this continuous feedback loop that the robot can interact with its environment such as walk, grasp or manipulate objects. When the robot shall also cope with unknown situations, its control system must be able to adapt and learn during operation. Thus, “learning” is a key characteristic of an autonomous system and spans all of its algorithmic components.
When robots and other autonomous systems are to be used in complex environments such as outdoors, we cannot foresee every possible situation that the robot needs to cope with. Thus, rigidly pre-programming robots is not a viable solution. Instead, the robot must be able to adapt and learn. The Autonomous Motion Department develops algorithms that leverage machine and statistical learning, as well as automatic control theory to increase the level of autonomy of future robotic systems.
For an autonomous system, such as a humanoid robot, to act precisely and robustly in its environment, it relies on continuous sensory feedback about its actions. This feedback loop is depicted in the above drawing: The robot’s controller perceives the robot’s motion and its environment through various sensors, processes the sensor data, and computes new action commands to be executed by the robot. The outcome of these actions is again observed by the sensors. It is through this continuous feedback that the robot is able to balance, walk, or manipulate an object, for instance. When the robot’s tasks are known in advance and the environment does not change significantly, well known methods exist to design such control systems. However, if the robot shall also cope with complex and unknown situations that cannot be pre-programmed, its control system must be able to adapt and learn from data and experience also during operation.
The “learning" component in the perception-action-learning system is thus a hallmark of autonomous systems. It is the ability to learn and to adapt to new tasks and a changing environment that makes human and non-human animals so superior to any artifact we have created so far. The Autonomous Motion Department has a specific focus on learning for control.
What is special about learning for control?
Learning control deserves a special status within the world of machine learning and statistical learning. In contrast to typically applications for machine learning, learning in the context of control and robotics constitutes a dynamic problem. The robot learns from the data that it generated through its own actions and perception system, as it decides where to go, what to look at, etc. The outcome of the learning, in turn, influences the robot’s behavior. For example, the robot acquires a new skill or improves its walking abilities. Thus, the learning process and the behavior of the robot influence each other and form a dynamic process. This has several implications:
- Instead of learning once from a given data set, the robot should continuously learn from the data it generates. Thus, learning must be fast, computationally and data efficient, and ideally continue forever without degradation.
- Since the robot generates its own data, there is often an interesting trade-off between exploiting of what has been learned so far, and trying to explore new parts of the world. This fundamental problem in learning control is known as the exploration-exploitation trade-off.
- Modern robotic systems have a rather high dimensional state, resulting from many sensors and a large number of degrees of freedom for movement. Thus, learning in hundreds, thousands, or even hundred thousands of dimension is not an unreasonable request. Dealing with this complexity, as well as detecting redundancy and irrelevancy are challenging requirements for learning control.
- Since the process of learning may alter the behavior of the robot, one must avoid wrong decisions to prevent physical harm to the environment and the robot. Thus, theoretical guarantees on robustness, stability, or confidence of actions are of great importance.
Learning Control at the Autonomous Motion Department
The Learning Control group in the Autonomous Motion Department has its focus on developing learning algorithms for control that can work in the above scenarios, ideally in a complete black box fashion, without the need to tune any open parameters and with convergence guarantees. Incremental learning with growing representational structure has been one of our main research thrusts, particularly in probabilistic setting of learning function approximators with local linear models. A second important topic is Reinforcement Learning; that is, how to improve movement execution from trial-and-error learning. Another topic addresses how to learn new feedback controllers from a large number of sensory feedback signals or feature vectors that are derived from sensory feedback.
Among others, we work on the following research topics:
- Incremental learning
- Reinforcement learning
- Learning by demonstration
- Learning of feedback controllers
- Automatic design and tuning of feedback controllers






