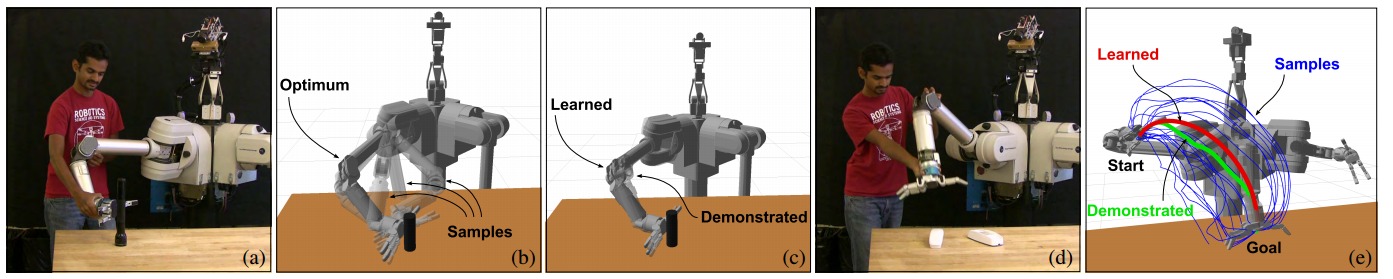
(a) Kinesthetic demonstration of a preferred kinematic configuration for grasping the flashlight. (d) Demonstration of a full trajectory from the home configuration to the grasp configuration.
Tuning and designing robotic behavior by combining elementary objective terms is a tedious task which generally consists of finding proper representations for each new skill. Inverse Optimal Control (IOC) allows, by specifying a set of basis functions (or features), to learn the right association of objective terms defining a policy imitating that of the expert. The Inverse Reinforcement Learning (IRL) formulation, where the generative model is formalized using a Markov Decision Process, was introduced in the early 2000 by Ng et al., and has since then received a lot of attention from the machine learning and robotics communities. At the Autonomous Motion Department, we seek to improve the state-of-the-art in IOC/IRL to learn motion policies for robotic systems from demonstrations as well as better understand and predict human motion. Hence we are interested in being able to specify a broad number of basis functions and handle the high-dimensional continuous cases involved in manipulation and motion generation.
Our path integral IRL algorithm can deal with such high-dimensional continuous state-action spaces, and only requires local optimality of the demonstrated trajectories. We use regularization in order to achieve feature selection, and propose an efficient algorithm to minimize the resulting convex objective function. Our approach has been applied to two core problems in robotic manipulation: Learning a cost function for redundancy resolution in inverse kinematics, and learning a cost function over trajectories, which is then used in optimization based motion planning for grasping and manipulation tasks.
We are also interested in enabling to handle noisy and incomplete demonstrations. Thus we have built on recent work in direct loss minimization structured prediction to suggest that IOC can be (counterintuitively) formalized as a form of policy search reinforcement learning. This connection allows to transition smoothly from imitating an expert to teaching itself over time, while handling noisy demonstrations. We use this procedure to calibrate our motion optimizers on Apollo.
Finally, we are studying how IOC can be used to define an optimality principle for human behavior by gathering human motion using a motion capture system. This optimality criterion can then be used to predict human motion through trajectory optimization. We have demonstrated this ability on the particular case of learning a model for collaborative manipulation task, where two humans perform an assembly task, and were successfully able to predict human reaching motion even when there is significant interference between the two partners.