
2023
Dhédin, V., Li, H., Khorshidi, S., Mack, L., Ravi, A. K. C., Meduri, A., Shah, P., Grimminger, F., Righetti, L., Khadiv, M., Stueckler, J.
Visual-Inertial and Leg Odometry Fusion for Dynamic Locomotion
In Accepted for IEEE International Conference on Robotics and Automation (ICRA), arXiv:2210.02127, 2023 (inproceedings) Accepted

2022
Büchler, D., Guist, S., Calandra, R., Berenz, V., Schölkopf, B., Peters, J.
Learning to Play Table Tennis From Scratch using Muscular Robots
IEEE Transactions on Robotics (T-RO), 38(6):3850-3860, 2022 (article)

2021
Yi, B. L. M. A. K. A. M. R. B. J.
Differentiable Factor Graph Optimization for Learning Smoothers
Proceedings 2021 IEEE/RSJ INTERNATIONAL CONFERENCE ON INTELLIGENT ROBOTS AND SYSTEMS (IROS), pages: 1339-1345, IEEE, IROS 2021, September 2021 (conference)
Leziart, P. F. T. G. F. M. N. S. P.
Implementation of a Reactive Walking Controller for the New Open-Hardware Quadruped Solo-12
Proceedings IEEE International Conference on Robotics and Automation (ICRA), pages: 5007-5013, IEEE, IEEE International Conference on Robotics and Automation (ICRA), June 2021 (conference)
Kloss, A., Martius, G., Bohg, J.
How to Train Your Differentiable Filter
Autonomous Robots, 45(4):561-578, Springer, June 2021 (article)
Hager, J., Bauer, R., Toussaint, M., Mainprice, J.
GraspME - Grasp Manifold Estimator
In 2021 30th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN 2021), pages: 626-632, IEEE, Piscataway, NJ, 30th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN 2021) , 2021 (inproceedings)
Oh, Y., Schäfer, T., Rüther, B., Toussaint, M., Mainprice, J.
A System for Traded Control Teleoperation of Manipulation Tasks using Intent Prediction from Hand Gestures
In 2021 30th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN 2021), pages: 503-508, IEEE, Piscataway, NJ, 30th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN 2021), 2021 (inproceedings)
Le, A. T., Kratzer, P., Hagenmayer, S., Toussaint, M., Mainprice, J.
Hierarchical Human-Motion Prediction and Logic-Geometric Programming for Minimal Interference Human-Robot Tasks
In 2021 30th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN 2021) , pages: 7-14, IEEE, Piscataway, NJ, 30th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN 2021), 2021 (inproceedings)
Oh, Y., Toussaint, M., Mainprice, J.
Learning to Arbitrate Human and Robot Control using Disagreement between Sub-Policies
In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2021), pages: 5305-5311, IEEE, Piscataway, NJ, IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2021), 2021 (inproceedings)

2020
Wüthrich, M., Widmaier, F., Grimminger, F., Akpo, J., Joshi, S., Agrawal, V., Hammoud, B., Khadiv, M., Bogdanovic, M., Berenz, V., Viereck, J., Naveau, M., Righetti, L., Schölkopf, B., Bauer, S.
TriFinger: An Open-Source Robot for Learning Dexterity
Proceedings of the 4th Conference on Robot Learning (CoRL), 155, pages: 1871-1882, Proceedings of Machine Learning Research, (Editors: Jens Kober and Fabio Ramos and Claire J. Tomlin), PMLR, November 2020 (conference)
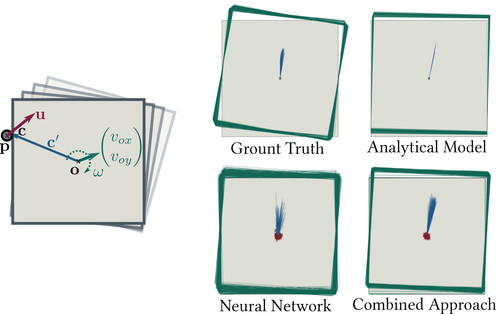
Kloss, A., Schaal, S., Bohg, J.
Combining learned and analytical models for predicting action effects from sensory data
International Journal of Robotics Research, September 2020 (article)
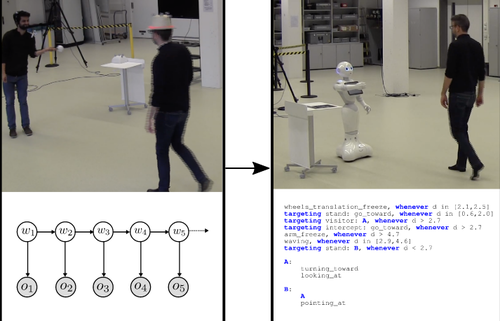
Berenz, V., Bjelic, A., Herath, L., Mainprice, J.
Learning Sensory-Motor Associations from Demonstration
29th IEEE International Conference on Robot and Human Interactive Communication (Ro-Man 2020), August 2020 (conference)
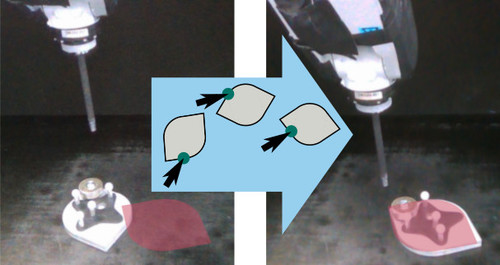
Kloss, A., Bauza, M., Wu, J., Tenenbaum, J. B., Rodriguez, A., Bohg, J.
Accurate Vision-based Manipulation through Contact Reasoning
In International Conference on Robotics and Automation, May 2020 (inproceedings) Accepted

Grimminger, F., Meduri, A., Khadiv, M., Viereck, J., Wüthrich, M., Naveau, M., Berenz, V., Heim, S., Widmaier, F., Flayols, T., Fiene, J., Badri-Spröwitz, A., Righetti, L.
An Open Torque-Controlled Modular Robot Architecture for Legged Locomotion Research
IEEE Robotics and Automation Letters, 5(2):3650-3657, IEEE, April 2020 (article)
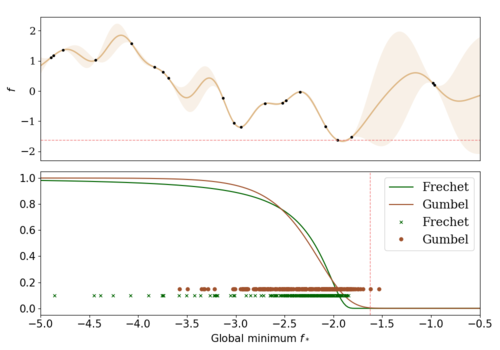
Marco, A., Rohr, A. V., Baumann, D., Hernández-Lobato, J. M., Trimpe, S.
Excursion Search for Constrained Bayesian Optimization under a Limited Budget of Failures
2020 (proceedings) In revision
Agudelo-España, D., Zadaianchuk, A., Wenk, P., Garg, A., Akpo, J., Grimminger, F., Viereck, J., Naveau, M., Righetti, L., Martius, G., Krause, A., Schölkopf, B., Bauer, S., Wüthrich, M.
A Real-Robot Dataset for Assessing Transferability of Learned Dynamics Models
IEEE International Conference on Robotics and Automation (ICRA), pages: 8151-8157, IEEE, 2020 (conference)
Mainprice, J., Ratliff, N., Toussaint, M., Schaal, S.
An Interior Point Method Solving Motion Planning Problems with Narrow Passages
In 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN 2020), pages: 547-552, IEEE, Piscataway, NJ, 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN 2020), 2020 (inproceedings)
Kratzer, P., Toussaint, M., Mainprice, J.
Prediction of Human Full-Body Movements with Motion Optimization and Recurrent Neural Networks
In 2020 IEEE International Conference on Robotics and Automation (ICRA 2020), pages: 1792-1798, IEEE, Piscataway, NJ, IEEE International Conference on Robotics and Automation (ICRA 2020), 2020 (inproceedings)
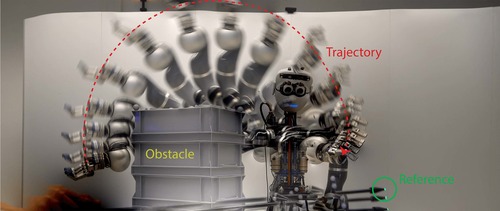
Nubert, J., Koehler, J., Berenz, V., Allgower, F., Trimpe, S.
Safe and Fast Tracking on a Robot Manipulator: Robust MPC and Neural Network Control
IEEE Robotics and Automation Letters, 5(2):3050-3057, 2020 (article)
2019
Gondal, M. W., Wüthrich, M., Miladinovic, D., Locatello, F., Breidt, M., Volchkov, V., Akpo, J., Bachem, O., Schölkopf, B., Bauer, S.
On the Transfer of Inductive Bias from Simulation to the Real World: a New Disentanglement Dataset
Advances in Neural Information Processing Systems 32 (NeurIPS 2019), pages: 15714-15725, (Editors: H. Wallach and H. Larochelle and A. Beygelzimer and F. d’Alché-Buc and E. Fox and R. Garnett), Curran Associates, Inc., 33rd Annual Conference on Neural Information Processing Systems, December 2019 (conference)

Sutanto, G., Ratliff, N., Sundaralingam, B., Chebotar, Y., Su, Z., Handa, A., Fox, D.
Learning Latent Space Dynamics for Tactile Servoing
In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) 2019, IEEE, International Conference on Robotics and Automation, May 2019 (inproceedings) Accepted
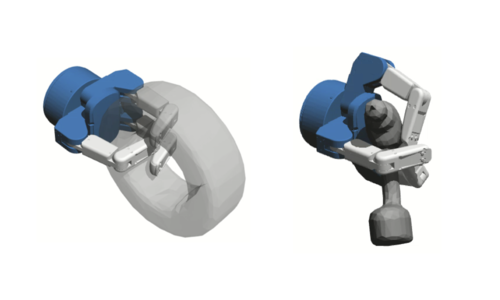
Merzic, H., Bogdanovic, M., Kappler, D., Righetti, L., Bohg, J.
Leveraging Contact Forces for Learning to Grasp
In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) 2019, IEEE, International Conference on Robotics and Automation, May 2019 (inproceedings)
Arslan, Ö.
Statistical Coverage Control of Mobile Sensor Networks
IEEE Transactions on Robotics, 35(4):889-908, 2019 (article)
2018
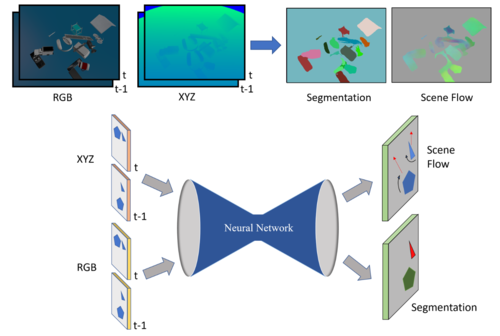
Shao, L., Shah, P., Dwaracherla, V., Bohg, J.
Motion-based Object Segmentation based on Dense RGB-D Scene Flow
IEEE Robotics and Automation Letters, 3(4):3797-3804, IEEE, IEEE/RSJ International Conference on Intelligent Robots and Systems, October 2018 (conference)

Anderson, M., Anderson, S., Berenz, V.
A Value-Driven Eldercare Robot: Virtual and Physical Instantiations of a Case-Supported Principle-Based Behavior Paradigm
Proceedings of the IEEE, pages: 1,15, October 2018 (article)
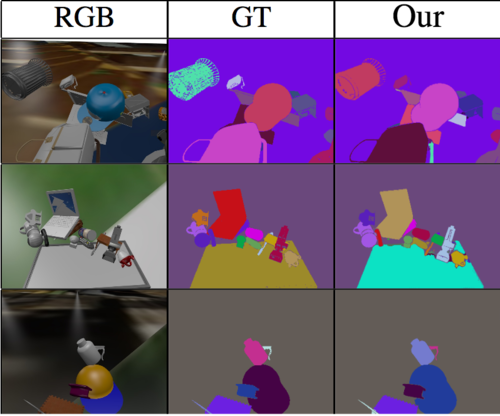
Shao, L., Tian, Y., Bohg, J.
ClusterNet: Instance Segmentation in RGB-D Images
arXiv, September 2018, Submitted to ICRA'19 (article) Submitted

Berenz, V., Schaal, S.
Playful: Reactive Programming for Orchestrating Robotic Behavior
IEEE Robotics Automation Magazine, 25(3):49-60, September 2018 (article) In press
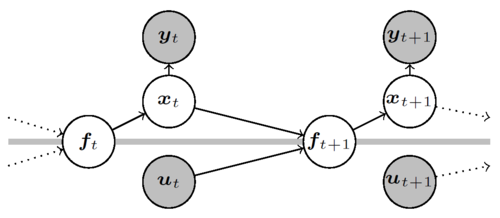
Doerr, A., Daniel, C., Schiegg, M., Nguyen-Tuong, D., Schaal, S., Toussaint, M., Trimpe, S.
Probabilistic Recurrent State-Space Models
In Proceedings of the International Conference on Machine Learning (ICML), International Conference on Machine Learning (ICML), July 2018 (inproceedings)

Kappler, D., Meier, F., Issac, J., Mainprice, J., Garcia Cifuentes, C., Wüthrich, M., Berenz, V., Schaal, S., Ratliff, N., Bohg, J.
Real-time Perception meets Reactive Motion Generation
IEEE Robotics and Automation Letters, 3(3):1864-1871, July 2018 (article)
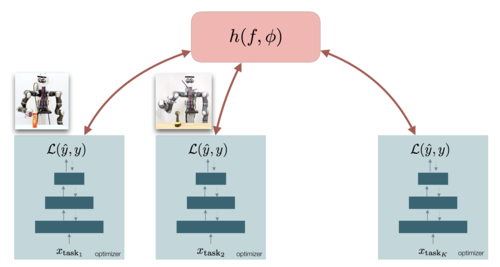
Meier, F., Kappler, D., Schaal, S.
Online Learning of a Memory for Learning Rates
In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) 2018, IEEE, International Conference on Robotics and Automation, May 2018, accepted (inproceedings)
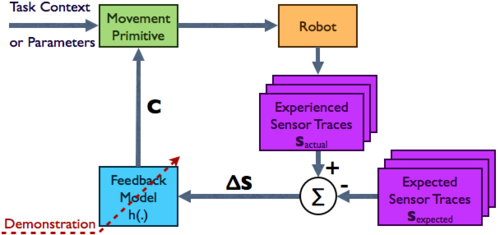
Sutanto, G., Su, Z., Schaal, S., Meier, F.
Learning Sensor Feedback Models from Demonstrations via Phase-Modulated Neural Networks
In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) 2018, IEEE, International Conference on Robotics and Automation, May 2018 (inproceedings)
Muehlebach, M., Trimpe, S.
Distributed Event-Based State Estimation for Networked Systems: An LMI Approach
IEEE Transactions on Automatic Control, 63(1):269-276, January 2018 (article)
Ponton, B., Herzog, A., Del Prete, A., Schaal, S., Righetti, L.
On Time Optimization of Centroidal Momentum Dynamics
In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages: 5776-5782, IEEE, Brisbane, Australia, 2018 (inproceedings)
Ascoli, A., Baumann, D., Tetzlaff, R., Chua, L. O., Hild, M.
Memristor-enhanced humanoid robot control system–Part I: theory behind the novel memcomputing paradigm
International Journal of Circuit Theory and Applications, 46(1):155-183, 2018 (article)
Baumann, D., Ascoli, A., Tetzlaff, R., Chua, L. O., Hild, M.
Memristor-enhanced humanoid robot control system–Part II: circuit theoretic model and performance analysis
International Journal of Circuit Theory and Applications, 46(1):184-220, 2018 (article)
Rotella, N., Schaal, S., Righetti, L.
Unsupervised Contact Learning for Humanoid Estimation and Control
In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages: 411-417, IEEE, Brisbane, Australia, 2018 (inproceedings)
Gams, A., Mason, S., Ude, A., Schaal, S., Righetti, L.
Learning Task-Specific Dynamics to Improve Whole-Body Control
In Hua, IEEE, Beijing, China, November 2018 (inproceedings)
Mason, S., Rotella, N., Schaal, S., Righetti, L.
An MPC Walking Framework With External Contact Forces
In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages: 1785-1790, IEEE, Brisbane, Australia, May 2018 (inproceedings)

2017
Hausman, K., Chebotar, Y., Schaal, S., Sukhatme, G., Lim, J.
Multi-Modal Imitation Learning from Unstructured Demonstrations using Generative Adversarial Nets
In Proceedings from the conference "Neural Information Processing Systems 2017., (Editors: Guyon I. and Luxburg U.v. and Bengio S. and Wallach H. and Fergus R. and Vishwanathan S. and Garnett R.), Curran Associates, Inc., Advances in Neural Information Processing Systems 30 (NIPS), December 2017 (inproceedings)
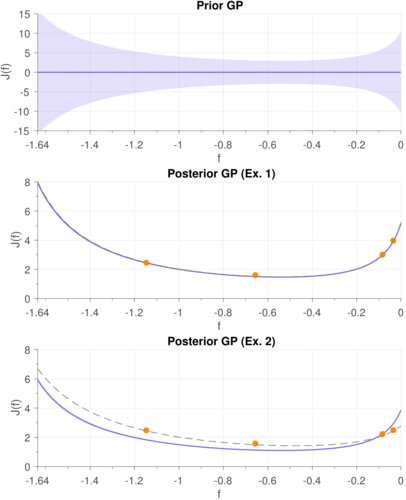
Marco, A., Hennig, P., Schaal, S., Trimpe, S.
On the Design of LQR Kernels for Efficient Controller Learning
Proceedings of the 56th IEEE Annual Conference on Decision and Control (CDC), pages: 5193-5200, IEEE, IEEE Conference on Decision and Control, December 2017 (conference)
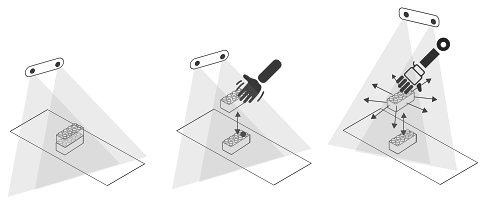
Bohg, J., Hausman, K., Sankaran, B., Brock, O., Kragic, D., Schaal, S., Sukhatme, G.
Interactive Perception: Leveraging Action in Perception and Perception in Action
IEEE Transactions on Robotics, 33, pages: 1273-1291, December 2017 (article)
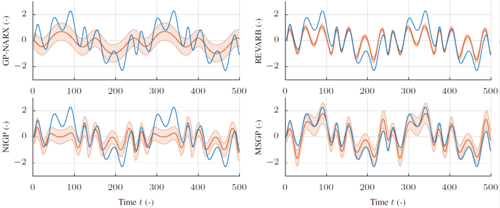
Doerr, A., Daniel, C., Nguyen-Tuong, D., Marco, A., Schaal, S., Toussaint, M., Trimpe, S.
Optimizing Long-term Predictions for Model-based Policy Search
Proceedings of 1st Annual Conference on Robot Learning (CoRL), 78, pages: 227-238, (Editors: Sergey Levine and Vincent Vanhoucke and Ken Goldberg), 1st Annual Conference on Robot Learning, November 2017 (conference)
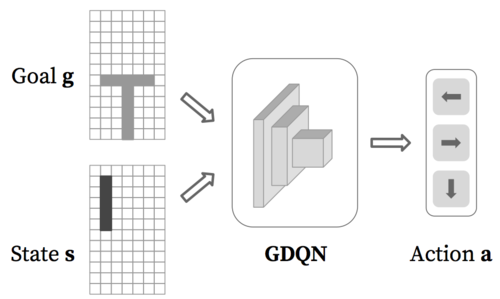
Li, W., Bohg, J., Fritz, M.
Acquiring Target Stacking Skills by Goal-Parameterized Deep Reinforcement Learning
arXiv, November 2017 (article) Submitted
Heijmink, E., Radulescu, A., Ponton, B., Barasuol, V., Caldwell, D., Semini, C.
Learning optimal gait parameters and impedance profiles for legged locomotion
Proceedings International Conference on Humanoid Robots, IEEE, 2017 IEEE-RAS 17th International Conference on Humanoid Robots, November 2017 (conference)
Kappler, D., Meier, F., Ratliff, N., Schaal, S.
A New Data Source for Inverse Dynamics Learning
In Proceedings IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Piscataway, NJ, USA, IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), September 2017 (inproceedings)
Fiebig, K., Jayaram, V., Hesse, T., Blank, A., Peters, J., Grosse-Wentrup, M.
Bayesian Regression for Artifact Correction in Electroencephalography
Proceedings of the 7th Graz Brain-Computer Interface Conference 2017 - From Vision to Reality, pages: 131-136, (Editors: Müller-Putz G.R., Steyrl D., Wriessnegger S. C., Scherer R.), Graz University of Technology, Austria, Graz Brain-Computer Interface Conference, September 2017 (conference)
Grossberger, L., Hohmann, M. R., Peters, J., Grosse-Wentrup, M.
Investigating Music Imagery as a Cognitive Paradigm for Low-Cost Brain-Computer Interfaces
Proceedings of the 7th Graz Brain-Computer Interface Conference 2017 - From Vision to Reality, pages: 160-164, (Editors: Müller-Putz G.R., Steyrl D., Wriessnegger S. C., Scherer R.), Graz University of Technology, Austria, Graz Brain-Computer Interface Conference, September 2017 (conference)
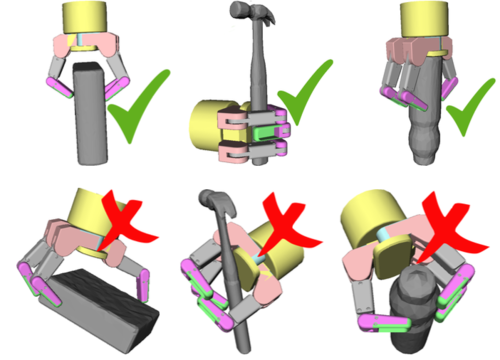
Rubert, C., Kappler, D., Morales, A., Schaal, S., Bohg, J.
On the relevance of grasp metrics for predicting grasp success
In Proceedings of the IEEE/RSJ International Conference of Intelligent Robots and Systems, September 2017 (inproceedings) Accepted
Akrour, R., Sorokin, D., Peters, J., Neumann, G.
Local Bayesian Optimization of Motor Skills
Proceedings of the 34th International Conference on Machine Learning (ICML), 70, pages: 41-50, Proceedings of Machine Learning Research, (Editors: Doina Precup, Yee Whye Teh), PMLR, August 2017 (conference)

Chebotar, Y., Hausman, K., Zhang, M., Sukhatme, G., Schaal, S., Levine, S.
Combining Model-Based and Model-Free Updates for Trajectory-Centric Reinforcement Learning
Proceedings of the 34th International Conference on Machine Learning, 70, Proceedings of Machine Learning Research, (Editors: Doina Precup, Yee Whye Teh), PMLR, International Conference on Machine Learning (ICML), August 2017 (conference)